
Letiția Pârcălăbescu
PhD, AI Researcher at Aleph Alpha Research
Deep Learning, LLMs, Vision and Language Models, Explainable AI, Interpretability

Letitia Parcalabescu has an academic background in Physics and Computer Science, and holds a PhD in Computational Linguistics. Her doctoral research focused on benchmarking and interpreting the internal processes and explanations of multimodal AI models. Currently, she is an AI researcher at Aleph Alpha Research, working on training interpretable reasoning models by design, as well as curating and synthesizing data for large-scale pre-training.
She created the "AI Coffee Break with Letitia" YouTube channel where she breaks down complex AI concepts. Topics range from newest research results in natural language processing, computer vision, to the broader societal impact of AI.
Highlights
YouTube Channel
Lighthearted bite-sized ML videos for your AI Coffee Break! 📺 Mostly videos about the latest technical advancements in AI, such as large language models (LLMs), text-to-image models and everything cool in natural language processing, computer vision, etc.!
Reviewing
ACL 2025 Area Chair (Meta-reviewer)
ICLR, ICML, Monthly *ACL Rolling Review (ARR), EACL, EMNLP, NAACL, ACL, CVPR, ACMMM, EurNLP
Workshops: MULA, RepL4NLP, LIMO
ACL2021 (Outstanding Reviewer)
Honors
ELIZA Fellow
ELIZA Fellow, Zuse School of Excellence in AI (ELIZA)
KlarText-Preis 2025
Recipient of the KlarText Award of the Klaus Tschira Foundation for science communication
Ruprecht-Karls Prize 2025
Recipient of the Ruprecht-Karls Prize of the Stiftung Universität Heidelberg for my PhD thesis
Nominated for the GI Dissertationspreis 2024, Dagstuhl
Nominated by Heidelberg University for my PhD thesis
Young Researcher at the Heidelberg Laureate Forum 2022
Recipient of the ABBE GRANT promoted by the Carl-Zeiss Stiftung
DAAD Vollstipendium Für Absolventen Deutscher Auslandschulen
Full scholarship to study the subject of my choice in Germany after graduating high school in Romania
Publications
Visit my Google Scholar page for a complete list. Selection:
Do Vision & Language Decoders use Images and Text equally? How Self-consistent are their Explanations?
Parcalabescu, L. and Frank, A., 2025., The Twelfth International Conference on Learning Representations (ICLR)
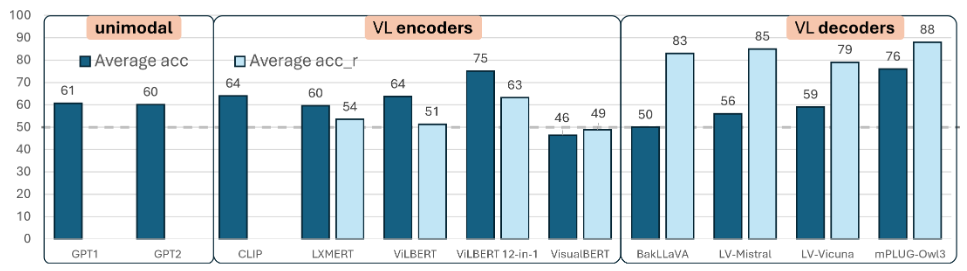
TLDR: Vision-and-language models (VLMs) – think GPT-4o – can answer questions about images and explain their reasoning. We measure how often VLMs hallucinate — in answers and in explanations. We also measure how much do these explanations and answers actually rely on the image.
Project in detail: I take a closer look at how VLMs combine vision and language when reasoning about visual input. Do they rely more on images when generating explanations than when producing answers? Are their explanations internally consistent? And how much do VLMs hallucinate? To find out, I tested today's top-performing VLMs on the VALSE benchmark I previously introduced.
To answer these questions, we apply established tools for measuring explanation faithfulness — including my previously introduced own methods — as well as my metric for quantifying modality usage. I compare model behavior across both post-hoc and chain-of-thought (CoT) explanation settings. The findings are striking: text dominates across the board, but the contribution of the image increases when models are asked to explain themselves — especially in CoT setups.
Finally, I present an up-to-date evaluation of modern vision-language decoders on the VALSE benchmark — which we designed a few years ago to test earlier-generation VLMs. The results? Despite recent advances, today’s models still struggle with grounded, image-based reasoning.
On Measuring Faithfulness or Self-Consistency of Natural Language Explanations
Parcalabescu, L. and Frank, A., 2024., Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024)
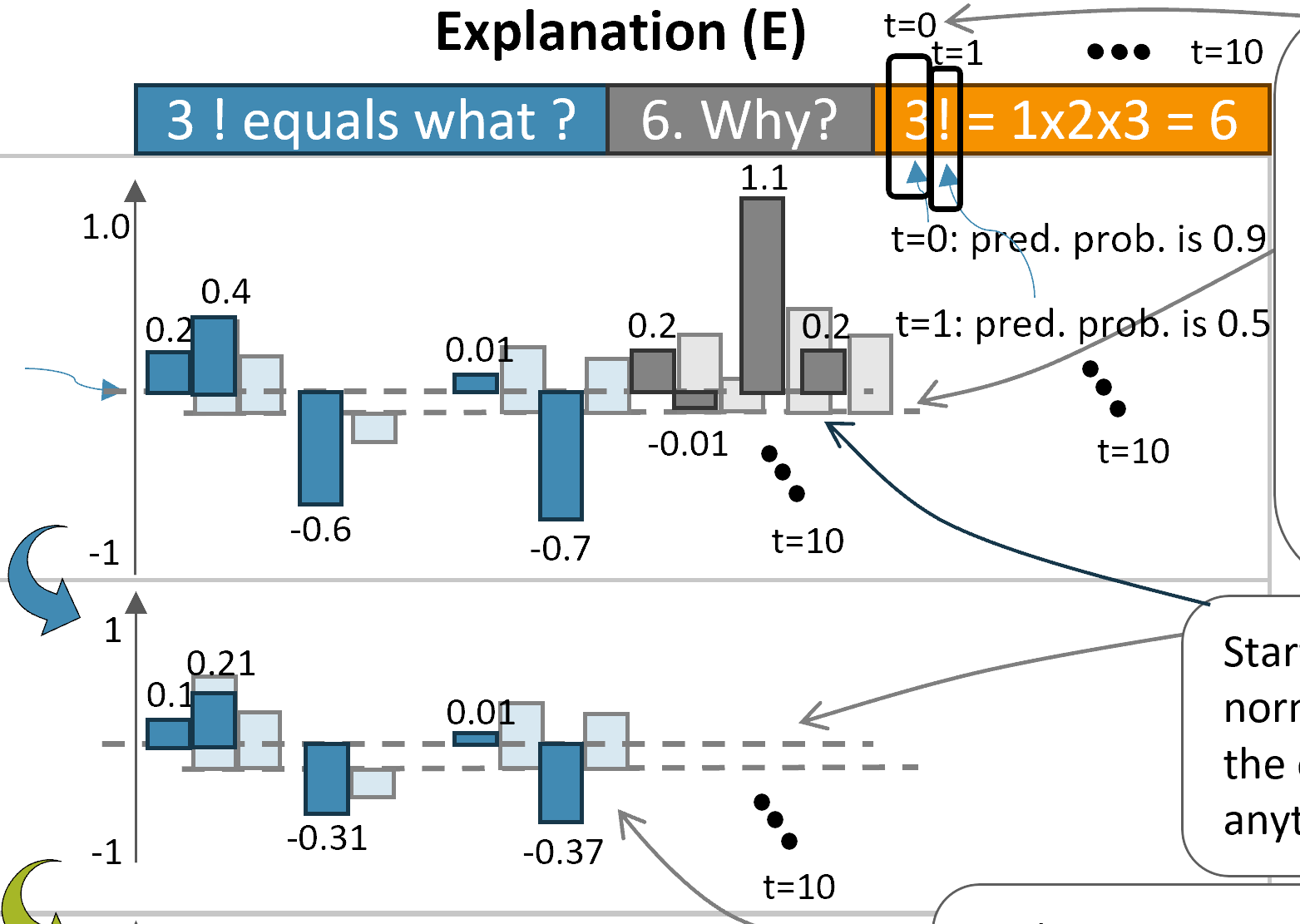
Are LLMs just making explanations up? Explanation hallucination is unfortunately a thing for LLMs!
Large language models can explain their answers — either after the fact (post-hoc) or step by step (Chain-of-Thought). But here’s the catch: sounding reasonable doesn’t mean being truthful. Many so-called “faithfulness tests” don’t actually peek into the model’s reasoning — they just check if the answer and explanation match on the surface.
In this project, we set the record straight: 🧠 We show that most “faithfulness” tests are really just self-consistency checks. 🧪 We introduce the Comparative Consistency Bank: the first large-scale comparison of existing tests across 11 open LLMs and 5 tasks.🔍 We propose CC-SHAP, a fine-grained metric that dives deeper: it compares how inputs influence both the answer and the explanation, shedding light on the model’s actual reasoning.
Faithfulness starts from the model internals — and CC-SHAP brings us closer to that.
ViLMA: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language Models
Kesen, I., Pedrotti, A., Dogan, M., Cafagna, M., Acikgoz, E.C., Parcalabescu, L., Calixto, I., Frank, A., Gatt, A., Erdem, A. and Erdem, E., 2023. The Twelfth International Conference on Learning Representations (ICLR)

Video-language models (VidLMs) are everywhere — but how well do they really understand what they see and hear over the entire video and how much do they hallucinate?
Enter ViLMA (Video Language Model Assessment): a task-agnostic benchmark designed to probe the fine-grained reasoning skills of VidLMs beyond surface-level performance. Unlike typical task-based evaluations, ViLMA focuses temporal understanding and visual grounding using carefully crafted counterfactuals and controlled setups.
ViLMA also includes proficiency tests to measure core abilities that VidLMs should have before solving more complex reasoning tasks.
The findings? Today’s VidLMs don’t perform any better than models trained on static images — even after accounting for basic proficiency.
MM-SHAP: A Performance-agnostic Metric for Measuring Multimodal Contributions in Vision and Language Models & Tasks
Parcalabescu, L. and Frank, A., ACL 2023, In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4032-4059, Toronto, Canada. Association for Computational Linguistics.

Multimodal models are supposed to combine information from both vision and language — but often, they cheat. When a unimodal model performs just as well as a multimodal one, it’s a red flag: unimodal collapse.
But relying on accuracy alone doesn’t tell the whole story. What if a model uses the right modality — but still gets the answer wrong?
That’s where MM-SHAP comes in. It’s a performance-agnostic metric based on Shapley values that quantifies how much a model relies on each modality — regardless of whether its prediction is right or wrong.
We use MM-SHAP to: 📊 Compare models by their average degree of multimodality, and 🧪 measure how individual modalities contribute across different tasks and datasets.
Applied to six vision-language models (including LXMERT, CLIP, and ALBEF variants) on four tasks, MM-SHAP reveals: unimodal collapse isn’t just common — it happens in different ways and directions.
💡 MM-SHAP helps you diagnose what’s going wrong and uncover hallucinations — and more importantly can help build truly multimodal models.
VALSE: A Task-Independent Benchmark for Vision and Language Models Centered on Linguistic Phenomena → Testing for VLM hallucinations
Parcalabescu, L., Cafagna, M., Muradjan, L., Frank, A., Calixto, I. and Gatt, A., ACL 2022 In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8253–8280, Dublin, Ireland. Association for Computational Linguistics.

Pretrained vision-and-language models (VLMs) may shine on standard tasks — but do they really understand the connection between images and language? When do VLMs start to hallucinate?
VALSE (Vision And Language Structured Evaluation) is a benchmark designed to find out which linguistic phenomena trigger VLMs to hallucinate. Rather than testing models on downstream tasks, VALSE zooms in on their ability to ground specific linguistic phenomena in the visual modality — things like spatial relations, counting, and negation.
VALSE includes six targeted tests, each crafted to reveal whether a model is truly connecting vision and language, or just guessing from shortcuts. We ensure high-quality examples through controlled construction methods and valid foils.
We tested five popular VLMs — and the results are sobering: most models struggle with core visio-linguistic reasoning.
With VALSE, we offer a finer lens for evaluating V&L models and tracking real progress — not just accuracy on tasks, but actual grounding and understanding.
Scientific Talks
- Invited lecture at the Karlsruhe Institute of Technology (KIT) by Prof. Tobias Käfer. (2026)
- Panelist in panel discussion on "Reasoning in AI", at the Zuse Schools anniversary event, Darmstadt (2025)
- Invited talk at the ETH Zürich by Prof. Menna El-Assady and Prof. Prof. Mrinmaya Sachan. (2026)
- Keynote Speaker, End-of-Year Symposium, research groups led by Prof. Lena Maier-Hein and Prof. Klaus Maier-Hein, German Cancer Research Center (DKFZ) (2025)
- Keynote speaker at the Marsilius Academy "AI and Human Values", Heidelberg (2025)
- Keynote at the Heidelberg Postdoc Symposium hosted by the German Cancer Research Center (DKFZ) (2025)
- Keynote at the National Conference on AI Transformations: Language, Technology, and Society, Utrecht (2025)
- Invited talk at the University of Sheffield NLP Group (2024)
- Invited talk at Datafest Yerevan Conference (2024)
- Invited talk at Aleph Alpha - Heidelberg (2024)
- Invited talk at cogsys-group, CLASP, Gothenburg, Sweden (2024)
- Podcast Interview Deep Learning with Letitia Parcalabescu - Weaviate Podcast #96! (2024)
- Invited to talk about on work at heidelberg.ai at the German Cancer Research Center (DKFZ) (2023)
- Invited Talk at the LIMO 2023 Workshop About Vision and Language (VL) models (2023)
- Invited talk about own work at the ICDM Workshop Foundation Models in Vision and Language (2022)
- Invited talk about own work “Multimodal Learning: Integrating Vision and Language” at StuTS 2020
Science Communication Talks
Talks for broader audiences:
- Podcast Guest, Dig Deep -- Künstliche Intelligenz (2026)
- Invited Speaker, UNESCO Campus Masterclass (global program on AI & media literacy), UNESCO (2026)
- Guest on the WiAIR Women in AI Research podcast (2026)
- Invited Speaker, "Lunch & Learn: KlarText zur Mittagszeit", Heidelberg University (2026)
- Panelist in the discussion "(How) can we trust AI in science?" at the Marsilius Kolleg, Heidelberg (2025)
- Speaker on the HLF AlumNode Panel Discussion "Social Media for Scientists – Opportunities and Challenges" (2025)
- Participated as a science communicator in the first Romanian-language Native Scientists Workshop Heidelberg (2025)
- Panelist at the VOICES festival in Zagreb, Croatia (2025)
- Talk and discussion "Artificial Intelligence: Which skills do I need?" at E-engAGEd organized by EAVI Media Literacy for Citizenship (2025)
- Panelist at the VOICES festival in Florence, Italy (2024)
- Invited to talk (in German) about AI for a general audience at ARD MixTalk (2023)
- Podcast (in German) about AI for the Handelsblatt (2023)
- Invited to talk in a panel about Digital Tools & AI in Research at To be honest Conference (2023)
- Panelist on the “Popularization in ML Research” panel at the ML in PL conference (2022)
- “AI for good” at the EAVI Conversations (2021)
- Guest on the Transformative Ideas Podcast
- Guest on the MLST YouTube channel and podcast
- “Why Multi-Modality is the Future of Machine Learning” at the ML Engineered Podcast
Teaching and Supervision
Teaching
Own courses organized independently at Heidelberg University, including lectures, exercises, exam / practical project
-
Methods for Learning without Annotated Data
Master Level Course (in English), every Summer Term from 2020 to 2024 with very good reviews
-
Designing Experiments For Machine Learning
Bachelor Level Course (in German), every Winter Term from 2021 to 2024 with very good reviews
-
Deep Learning Course for Biologists
at the HBIGS graduate school Heidelberg every term since 2023
-
Programming Exam
Summer Term 2020, Winter Term 20/21
-
Resource course
Bachelor Level Course (in German) Summer Term 2020, Winter Term 20/21
-
Integrating Vision and Language: Achievements and Challenges in Multimodal Machine Learning
Master Level Seminar, Winter Term 19/20
Supervision
Currently supervising two PhD Students at Aleph Alpha Research. Completed: Co-supervision of theses with Prof. Anette Frank:
- Master theses: Phillip Wiesenbach, Julia Suter
- Bachelor thesis: Lillita Muradjan